scrapy框架学习
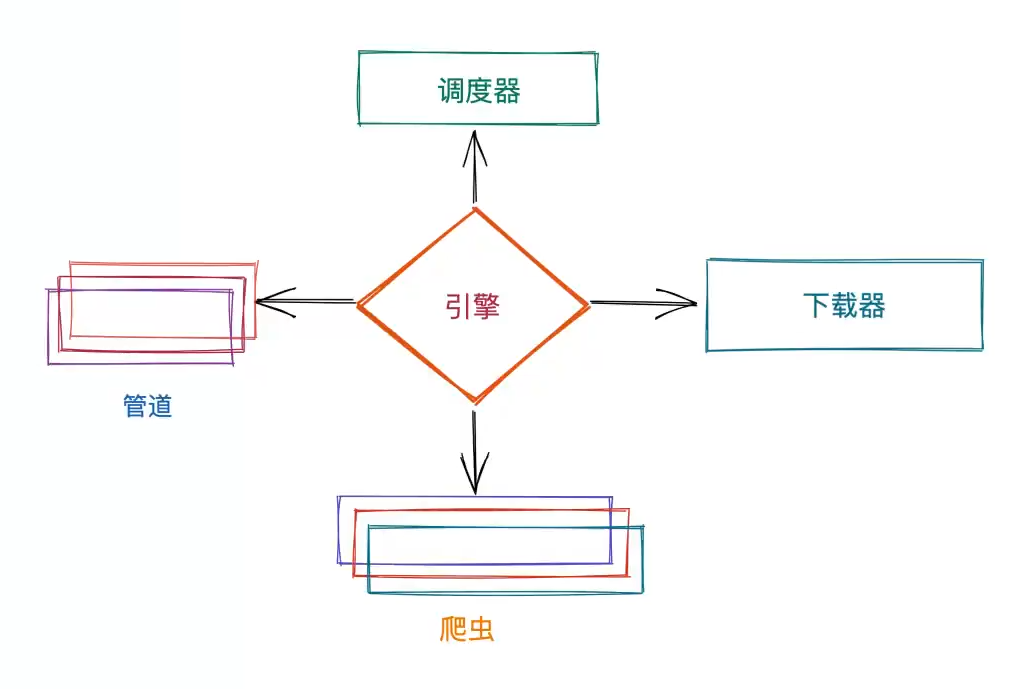
整体框架
下载
1
2
| pip install scrapy
scrapy version
|
创建scrapy项目
1
| scrapy startproject test
|
文件目录:
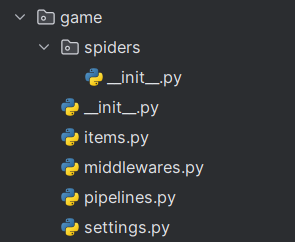
spiders中存放爬虫middelwares.py为中间件文件,很重要pipelines.py为管道文件,用于文件的传输和存储方法settings.py为配置文件
运行项目
运行单个爬虫
创建爬虫
1
2
| # scrapy genspider "爬虫名字" "限制域名"
scrapy genspider bilibili bilibili.com
|
此操作将在spiders文件夹中创建bilibili.py文件
需要重写里面的parse函数
爬取文章名称和url
1
2
3
4
5
6
7
8
| with open("shaun.txt", "w", encoding="utf-8") as f:
article = response.xpath("//article")
card_list = article.xpath("./div/div/div[@class = 'card']")
for card in card_list:
title = card.xpath("./a/div/span/text()").extract_first()
href = card.xpath("./a/@href").extract_first()
url = response.urljoin(href)
f.write(f"{title}, {url}\n")
|
爬虫
重写新建爬虫中的parse函数
该函数是用于处理返回的数据
可以使用yield 'data' 进行向管道传递数据,’data’需要替换为具体的数据。
也可以在该方法中直接调用一些接口进行储存
1
2
3
4
5
6
7
| class BilibiliSpider(scrapy.Spider):
name = "bilibili"
allowed_domains = ["bilibili.com"]
start_urls = ["https://bilibili.com"]
def parse(self, response):
print(response.text())
|
对于爬取到的url继续进行爬取
使用yield scrapy.Request进行实现
管道
在pipeline中完成数据传输
1
2
3
4
5
| class 类名:
def process_item(self, item, spider):
returnitem
|
将数据存入文件
关于将数据存到文件里的情况,若每次存一条数据都打开文件再关闭,效率过低
因此,需要在开始存数据之前打开文件,在所有数据存好了之后再关闭
scrapy框架中给了两个方法可以进行重载,以完成上述功能
1
2
3
4
5
6
7
8
9
10
11
12
13
| class CaipiaoPipeline:
def open_spider(self, spider):
self.f = open("./data.csv", "a", encoding = "utf-8")
def close_spider(self, spider):
if self.f:
self.f.close()
def process_item(self, item, spider):
self.f.write(f"{item['qihao']}, {'_'.join(item['red_ball'])}, {item['blue_ball']}\n)
return item
|
将数据存入数据库
思路和上面一样,只是把那两个函数的实现改成连接数据库和关闭数据库即可。
